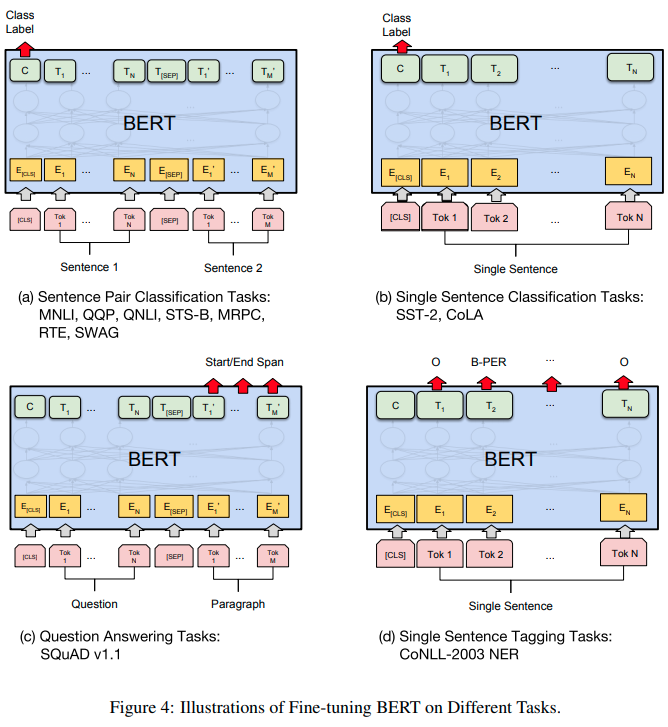
BERT 정의: 문맥을 양방향으로 이해해서 숫자로 바꿔주는 딥러닝 모델 기존 모델과의 비교 ELMo: 정방향, 역방향으로 학습하여 hidden state들의 linear 결합을 통해 최종 token 도출 GPT: decoder를 사용하여 후반부 단어들 masking 시켜놓고 다음 단어를 예측하는 방식으로 학습 BERT: encoder를 사용하여 방향성 없이 한꺼번에 모두 처리, masked 단어를 예측하는 방식으로 학습 SQuAD, NER, MNLI 같은 layer 1개만 BERT 위에 쌓음으로써 기존 모델들을 앞지를 수 있는 우수한 성능을 보인다. 모델 아키텍쳐 transformer의 encoder 블록만 사용 Sentence: 일련의 연속적인 text, 완벽한 문장이 아니어도 됨 (rather tha..