BERT 정의: 문맥을 양방향으로 이해해서 숫자로 바꿔주는 딥러닝 모델
기존 모델과의 비교

- ELMo: 정방향, 역방향으로 학습하여 hidden state들의 linear 결합을 통해 최종 token 도출
- GPT: decoder를 사용하여 후반부 단어들 masking 시켜놓고 다음 단어를 예측하는 방식으로 학습
- BERT: encoder를 사용하여 방향성 없이 한꺼번에 모두 처리, masked 단어를 예측하는 방식으로 학습
SQuAD, NER, MNLI 같은 layer 1개만 BERT 위에 쌓음으로써 기존 모델들을 앞지를 수 있는 우수한 성능을 보인다.
모델 아키텍쳐
- transformer의 encoder 블록만 사용
Sentence: 일련의 연속적인 text, 완벽한 문장이 아니어도 됨 (rather than an actual linguistic)
Sequence: a single sentence or two sentences packed together
[CLS]: sentence의 시작을 나타내는 token
[SEP]: 두 개의 sentence 사이를 구분하는 token
- Input/Output representation
- Input : a single sentence and a pair of sentences (Question-Answer)
1. Token embedding
WordPiece Embedding
단순 띄어쓰기가 아닌 Texting → [Text, ##ing] 식으로
→ 신조어, 오탈자가 있는 입력값도 처리 가능
2. Segment embedding
2개의 문장이 입력될 경우, 각각의 문장에 서로 다른 숫자를 더함
→ 서로 다른 문장이 있다는 정보 제공
3. Position embedding
sin, cos와 같은 주기함수 사용
→ token의 상대적 위치 정보 제공
- 상대적 위치를 사용하는 이유: 최장길이를 settting 하지 않기 위해서
- Bert의 목적: MLM, NSP 2개의 task를 같이 학습시키는 것
Pre-training BERT
Task 1: Masked Language Model (MLM)
- 15%의 sequence가 Mask token으로 바뀜
- ELMo 는 순차적으로 정방향, 역방향 모두 따로 학습을 해서 선형 결합을 하는데, Bert는 masking 해놓고 모델이 masked된 단어를 잘 예측하도록 학습시킴
- fine-tuning 단계에서는 masking 없음 → 그럼 pre-training 과 fine-tuning 간의 mismatch가 있을 수 있지 않은가 → random token(10%), unchanged token(10%)으로 해결할 수 있다.
Task 2: Next Sentence Prediction (NSP)
- ELMo, GPT는 문장 단위로 학습을 진행하기에 문장 사이의 관계를 다루는데 취약하다.
- 학습방법: IsNext, NotNext로 label을 1, 0으로 주어 학습시킴 (단순한 아이디어지만 큰 효과)
Fine-tuning BERT
- GPT에는 없는 단계로, 윗단에 layer만 걸쳐놓으면 어떠한 모델도 태울 수 있다.
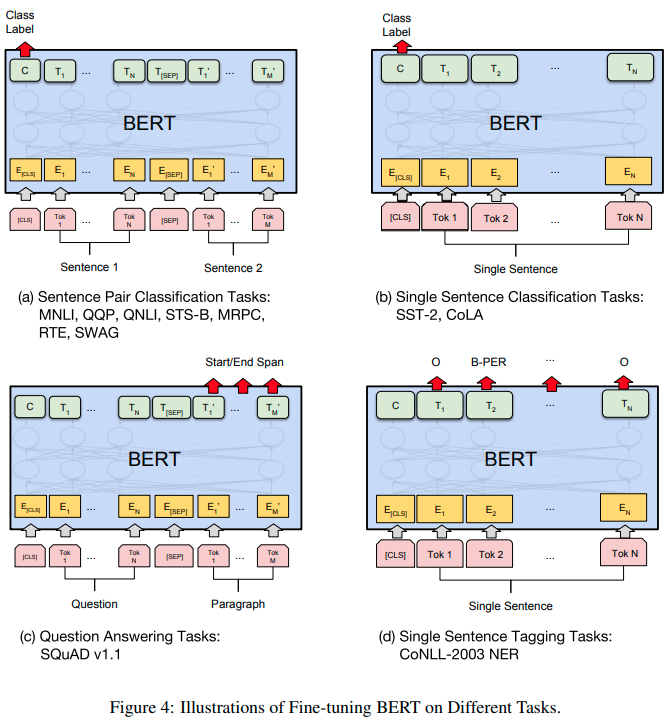
pretrained 된 bert는 쉽게 다운받을 수 있다.
방법 4개를 논문에서 소개하고 있다.
1) 두 문장 관계 예측, 출력의 첫번째 c - cls token으로 두 문장의 관계를 나타냄
2) 문장을 분류, cls 토큰이 분류값 중 하나를 갖도록
3) 질문과 정답이 포함된 장문 받아 출력 마지막 token들이 첫, 마지막 index를 갖도록 한다.
4) 문장 속 단어를 tagging
'theory > NLP' 카테고리의 다른 글
| [머신러닝 기초] 학습 유형 (0) | 2023.05.07 |
|---|---|
| [머신러닝 기초] entropy, binary cross entropy, KL divergence (0) | 2022.09.26 |
| Transformer (0) | 2022.02.04 |
| 퍼셉트론(perceptron) (0) | 2022.01.17 |
| sparql이란? (0) | 2021.03.22 |